
Identity proliferation, access sprawl, over-provisioned access, and reviewer fatigue will continue to grow in your identity ecosystem. In the rapidly evolving landscape of identity security and governance platforms, a few tipping point technologies have emerged. The potential is immense – how do you harness the power? Right start your identity strategy with advanced analytics and AI.
In this series of blogs, we’ll delve into analytics, AI, automation, and abstraction: what are they, which design is best for identity platforms, and how you can leverage them effectively.
Tipping Point #1 – Intelligent Analytics:
Traditionally, identity platforms have employed clustering algorithms to define peer groups, using them to construct access analytics and recommendations. However, using statistical algorithms to derive access analytics has some notable shortcomings.
Static Parameters Don’t Fit Dynamic Organizations
Organizations are constantly undergoing structural reorganizations, divestitures, and spin-offs, as well as experiencing new joiners, internal transfers, and departures. But clustering algorithms rely on static parameters and attributes to generate peer groups. This rigid approach results in generating peer groups that can quickly become outdated and generate stale recommendations with low confidence.
Human Reliance
The effectiveness of the platform depends on app and system owners manually selecting and fine-tuning attribute combinations, which can be a time-consuming trial-and-error process.
Lack of Feedback Loop
In the current system, usage data is not integrated into the recommendations engine, preventing the system from learning and refining its recommendations over time.
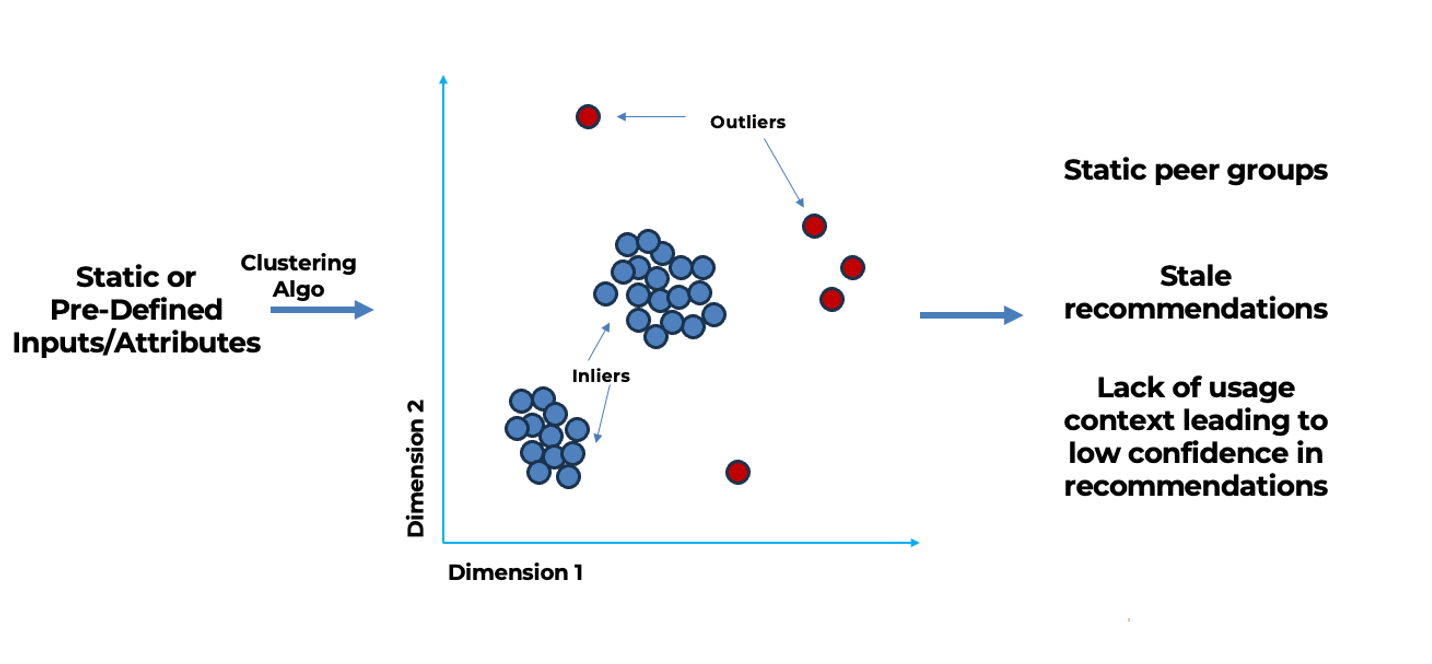
Limitations in current implementations of recommendation algorithms
3 Steps to Building Intelligent Access Analytics
For CISOs seeking to elevate their organization’s security infrastructure, understanding and implementing intelligent access analytics is not just beneficial—it’s essential for staying ahead in a rapidly evolving digital landscape.
The first steps of this innovative approach include:
- Determine the most relevant peer groups based on users, access, and application types.
- Dynamic and intelligent recommendations based on multi-dimensional peer groups can reduce the reliance on humans.
- Context-driven algorithms making use of identity, access, usage, and internal/external risk signals provide intelligent, high-confidence, dynamic recommendations. Ingesting usage allows the platform to learn, fine-tune, and improve its findings and model coverage, as well as the efficacy of the recommendations.

These steps translate into attractive benefits:
- Enhanced scalability. Processing larger quantities of security data across diverse identity types drives greater efficiency. Prioritizing the detection of outlier access and risky entitlements improves overall resource use.
- Strengthened security measures. Bolster security controls to proactively mitigate over-provisioning risks. Recommendations are generated through a comprehensive analysis of identity attributes, access permissions, user activity, and risk indicators.
- Reliable, intelligent automation. Access approvals are granted based on usage patterns; low-risk cases can be automatically granted with a high degree of confidence.
- Substantial cost reduction. Automating the detection, restriction, and monitoring of outlier access minimizes human involvement and shrinks overhead.
Tipping Point #2 – Rise of AI
In 2023, the spotlight was on AI, with technologies like ChatGPT and Bard garnering significant attention. This transformative year also marked a beginning of a significant shift in the realm of identity platforms. These platforms are now ready for a substantial transformation through their integration with Large Language Models (LLMs), reshaping the dynamics of human and digital identity interactions within the domain of identity security.
However, a word of caution. Constructing a GenAI-based integration for enterprise-ready identity security and governance platforms demands meticulous effort. While the potential of LLMs is immense, even the most powerful, pre-trained LLMs may not immediately align with your specific requirements.

First, it’s imperative to know the basics of various design patterns—and which ones are more practical and effective to implement in the realm of identity security and governance landscapes.
There are several fundamental principles to consider.
- Identity data often lacks essential metadata or proper classifiers, leading to potential inaccuracies.
- Identity platforms are highly tailored to individual businesses, necessitating a strong demand for customized outputs.
- Pre-trained LLMs may lack awareness of specific workflows and processes crucial to your identity platforms. For instance, when handling technical queries related to particular requests or user manager campaigns, the LLM’s accuracy may falter if it lacks access to the right instruction manuals.
- Identity security and governance platforms employ distinct terminologies, concepts, and structures not prominently featured in general pre-training data. A pre-trained LLM may encounter challenges when summarizing information or responding to queries related to financial data, medical research papers, or even transcripts from company meetings.
4 Ways To Integrate LLMs With Business-Specific Data
To address the specific requirements of identity platforms, there are four design patterns with their pros and cons as defined below.
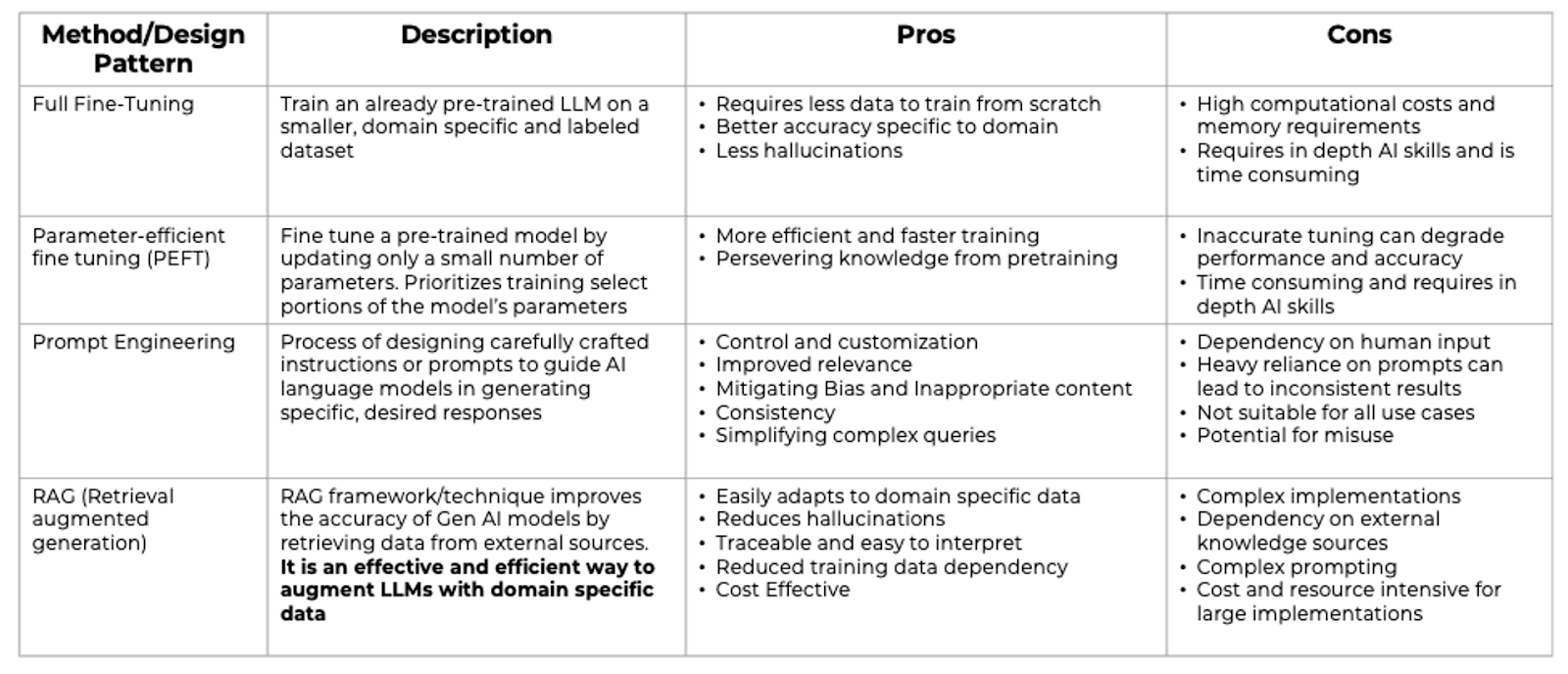
Design Patterns/Techniques to integrate LLMs with business/domain specific data
‘Prompt Engineering‘ and ‘Retrieval Augmented Generation (RAG)‘ models cater to practical necessities by offering refined control and customization. Prompt Engineering is the meticulous crafting of prompts to guide the AI in generating precise and relevant responses. It helps in simplifying complex queries and ensures consistency while mitigating bias and inappropriate content.

On the other hand, the RAG model augments the generative capabilities of LLMs with information derived from external and business-specific data sources. It’s an efficient way to enhance LLMs with domain-specific knowledge, reducing the dependency on large training datasets, and lowering the chances of generating incorrect information or “hallucinations”. This model is particularly effective for applications where accuracy and up-to-date information are critical and is suited well for the identity landscape.
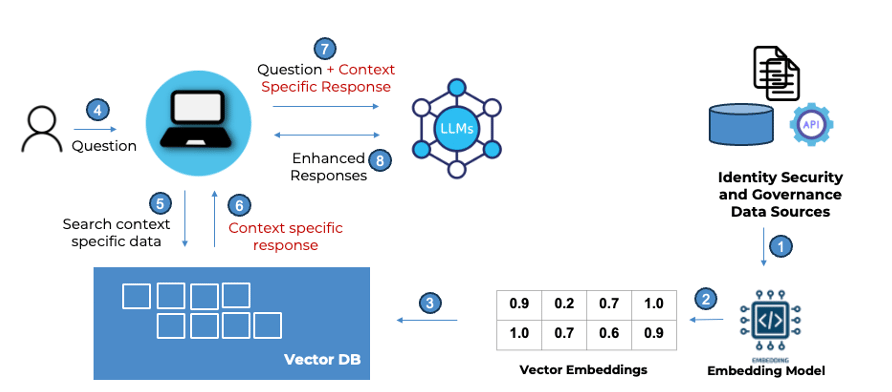
Integrating Identity security platforms data with LLMs using Retrieval Augmented Generation frameworks
Which Design is Best?
When choosing between design patterns, there are three key metrics to account for.
Cost
Prompt Engineering tends to be the most cost-effective among all the four patterns followed by RAG implementations. RAG is higher in terms of cost because of the need for multiple components including vector stores, retrievers, and embedding models
Implementation Complexity
Again, Prompt Engineering and RAG are the two design paradigms that are less complex when compared to PEFT and Full Tuning.
Accuracy
This is the most important metric for an identity security platform. RAG is clearly a winner when it comes to getting accurate results across multiple dimensions, including the latest responses, reduced hallucinations, transparency, and interpretability.
Reducing hallucinations is an especially sensitive metric to track and will require specific design patterns to be implemented (more to come on this in subsequent articles).
Last but not least, building responsible and secure AI integrations and adhering to the guidance published by government agencies will be extremely important (USA Executive Order, The EU AI Act, Canada AI and Data Act). More to come on Automation and Abstraction. Stay tuned!
At Saviynt, we’re on a journey to reshape and redefine the identity security and governance landscape. Come collaborate with us and be a part of this future!





Report
Saviynt Named Gartner Voice of the Customer for IGA
EBook
Welcoming the Age of Intelligent Identity Security

Press Release
AWS Signs Strategic Collaboration Agreement With Saviynt to Advance AI-Driven Identity Security

Solution Guide