What is Machine Identity and Machine Identity Management?
What is a Machine Identity?
Machine identities are software-based network “users” that are a subset of the broader category of “identities” which include humans, including both your employees and customers.
Examples of machine identities include Application Programming Interfaces (APIs) and Robotic Process Automation (RPAs or “bots”). They do the background jobs such as connecting services across the cloud ecosystem or managing repetitive administrative tasks.
These silicon-based “users” interact with sensitive company and personally identifiable information (PII) just as typical human users do. Organizations leveraging cloud-first or cloud-only strategies require an important integration, or a point of convergence, between both Identity Governance and Administration (IGA) and Privileged Access Management (PAM) systems, and machine identities.
Organizations rely on these machine identities to transmit and collect data. To secure this data, most organizations start by implementing common security tools, such as gateways, encryption, or key management solutions. However, these tools are an important part of in-depth defense strategy. Managing machine identities' security means treating them as any other identity, ensuring that they have the right access to the right resources at the right time.
Types of Machine Identities
Machine identities can be broken into two categories: workloads and devices. Workloads include containers, virtual machines, applications, services, RPAs (bots), and scripts—while devices include mobile, desktop, and IoT devices.
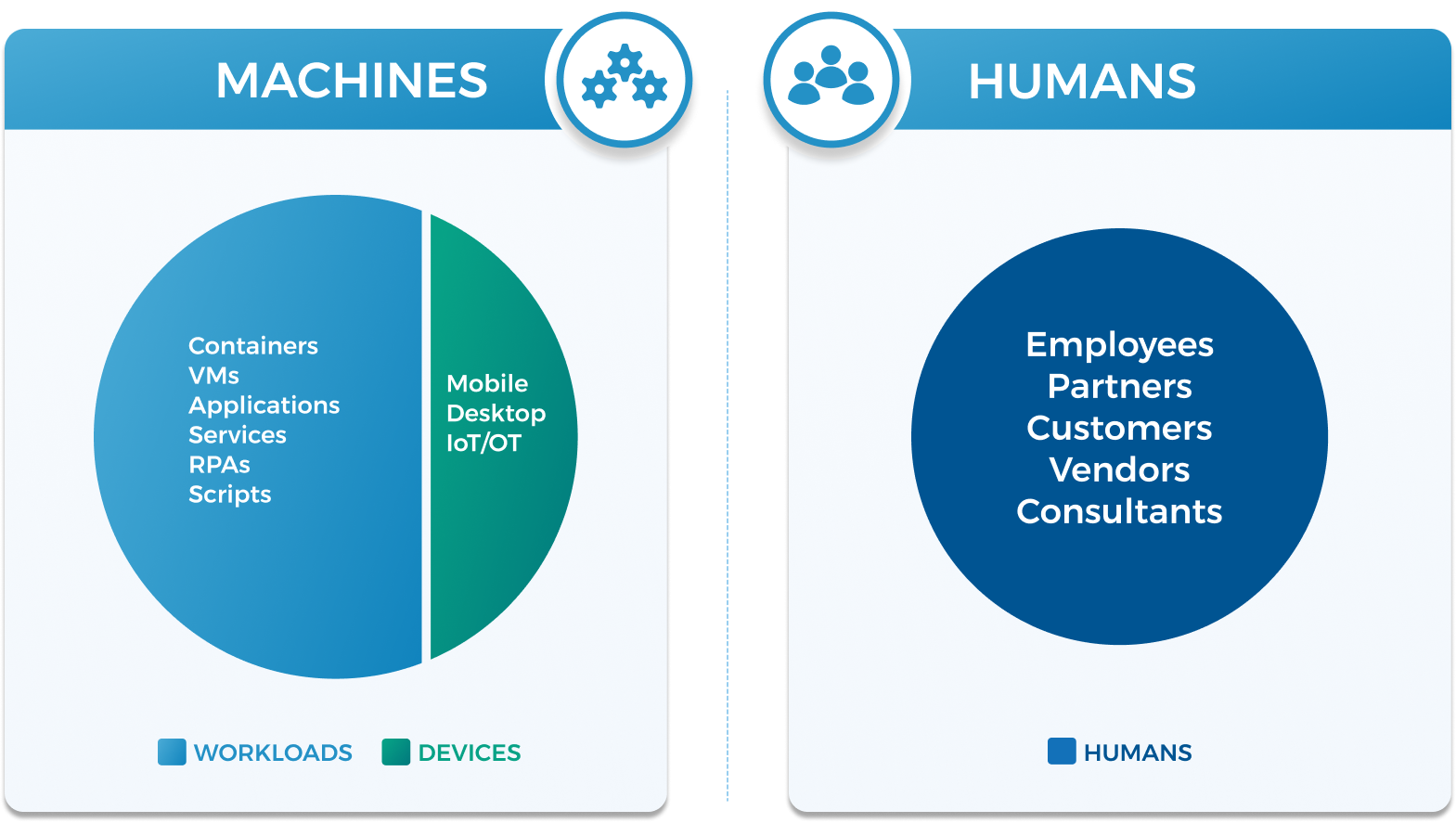
Workloads
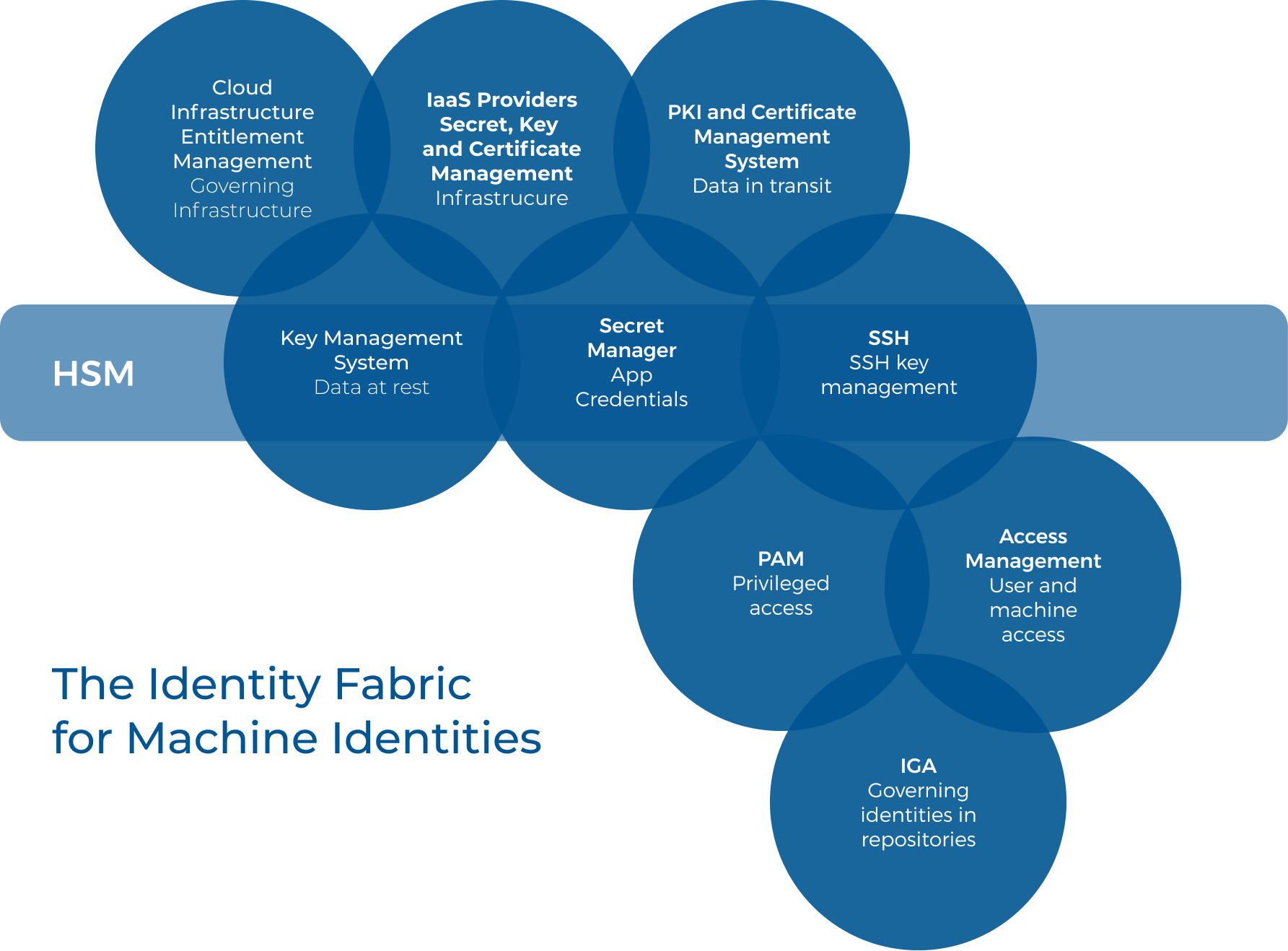
Workloads represent a broad and diverse area and in comparison to devices, the definition of workloads is incomplete. Gartner notes that clients commonly ask for a single solution to manage workloads, but best practices for managing them are still forming. They go on to say, “the industry needs consolidation and further work when it comes to definitions, naming standards and cross-platform tooling, so a best-of-breed strategy is typically adopted by organizations.” And while “…there are efforts to synchronize identities, govern multiple policy-compliant secrets managers, and PKIs and identities used in multi-cloud environments. No single tool, however, exists for all use-cases, disregarding what your vendors say.”
Gartner developed this figure to outline the tools in organizations’ identity fabric that manage workloads ranging from built-in functionality in IaaS provider platforms to third-party software and hardware security modules.
Let’s have a look at two of the most common workloads that organizations must work to secure:
RPAs (or “bots”) are code-driven, robotic processes that act just like a human user by completing repetitive activities. They are easy to use, often with a low-code or no-code implementation. Bots can effectively manage high-volume, repeatable tasks such as queries, calculations, and record/transaction maintenance. Some RPAs log in to applications and enter data automatically, enhancing the efficiency of employees by reducing the number of repetitive tasks they need to do their jobs.
Application Programming Interfaces (APIs) serve as an interaction and integration point for applications, often providing access to public cloud and Software-as-a-Service applications. More often than not, companies seeking to update a legacy application use APIs to create modernized versions of their technology. Most modern applications leverage a private or public API stack to simplify enterprise data access and integrations.
Devices
Devices are physical computers, including mobile phones, desktop computers, and Internet of Things (IoT) and operational technology (OT) devices. Unlike workloads, there are mature tools for managing multiple types of devices and their credentials. Mobile devices and desktop computers are typically managed using unified endpoint management (UEM) tools, while the device diversity of IoT devices has resulted in a lack of best practices and a need for innovation in the solutions that attempt to secure them.
Machine Identity Management Challenges
One risk when dealing with machine identity management is the challenge of continuously monitoring how machine identities’ access data. While everyone agrees on the value of RPAs to increase operational efficiency, organizations must find a way to limit the access bots have to their environments. AWS Lambda and Azure Functions offer examples of this challenge. These serverless technologies build security into the functions and offer varying monitoring and alerting capabilities. Those protect how the functions access information. However, these capabilities don’t provide visibility into the users who manage and change these functions.
Another machine identity management challenge is managing API access risk. Gateways generally regulate API access, acting as an entry point. Many times, customers have already integrated their API oversight with multi-factor authentication (MFA), single sign-on (SSO), and Identity-as-a-Service (IDaaS) solutions. Most customers even have an Access Control List (ACL) or role-based rule sets to control authorization. These controls facilitate authentication and, often, authorization. However, they don’t extend governance over who controls the APIs themselves. Organizations rightfully worry about who controls and codes these machine identities. Some of the questions that come up include:
- Who or what can access and use my machine identities?
- How can I monitor and control access requested, granted, or updated?
- Who has the ability to modify/update/delete machine identities?
- Who is the machine identity owner or “steward”?
- How do I transfer machine identity ownership?
- What privileged access are my machine identities invoking (keys and credentials)?
- How can I review and maintain all of the documentation necessary (including implementing compensating controls and mitigating controls) to comply with regulatory and industry standards’ mandates?
This keys for machine identity survey further elaborates on these challenges, especially around API keys and mandatory key strength and the fact that so few organizations recognize these risks.
To tackle the questions above and secure machine identities, organizations must create an “identity-centric approach,” establishing and enforcing lifecycle management processes over their machine identities. This approach should be similar to the way they govern human users while also allowing for the differences between the two.
Machine Identity Security: How to Secure Machine Identities
Manage Machine Identity Lifecycle
First and foremost in machine identity security, you need to assign a unique identifier to each machine identity so that you can provision access and enforce policies as part of your lifecycle management process. Putting governance around the identity and being able to track it becomes a critical step in securing your data.
Define Machine Identity Access
Machine identities fundamentally behave as privileged users. The type of tasks they do may seem mundane, but their privileged access represents a security or privacy threat to your company. Organizations must elevate privilege on a just-in-time basis and deactivate the privilege when the machine identity is not active. They need to review what access these identities have and what resources they access to ensure they have the least privilege necessary. They need visibility into whether access is revoked or otherwise changed to ensure compliance with internal policies.
Associate Owner or Responsible Party with Machine Identity
Associating a responsible party or ownership helps protect organizational data. Machine identities, once set, often stay in place longer than employees. Organizations must align users to individual machine identities or families/groups of machine identities, so they have a human user tied back to the activities. They need to create succession policies in case the responsible party leaves the company or moves to another role. The responsible party fulfills attestation needs, while succession management ensures that someone is always able to be in that role.
Continuously Monitor for New Risks
In the same way, organizations develop intelligence around human users, they need to monitor for new risks from machine identities. Security and privacy regulations and standards are constantly changing and evolving. A common thread among these compliance mandates is the need to continuously monitor for new risks. The velocity and volume of the cloud means that new risks can surface rapidly. While we still need to do periodic access reviews, we also know that point-in-time compliance no longer equates to security. Peer and usage data can help surface new threats by alerting you to outliers. For example, assume you set a rule that your APIs make calls to the application every fifteen minutes. Taking an “identity-centric” approach requires you create time-bound account elevation requests that are automatically approved every time the API makes the call. If you suddenly get a notification of the API requesting access every ten minutes, the request is an outlier that signals a potential new risk. Organizations need a way to engage in continuous control monitoring to protect themselves from compliance violations.
Identify “Rogue” Machine Identities
While applicable to both APIs and RPAs, rogue machine identification is easiest to understand when thinking about bots. Many times, DevOps users re-use code from one RPA to another. However, if the new bot engages with a more sensitive data type, such as PII, then the old code may leave you open to risk. By taking an “identity-centric” approach, you can monitor what information the machine identities interact with so that you can better control whether they need that access or need the access in the way provisioned.
Deactivate or Disable the Machine Identity
If you detect a new risk, such as a rogue bot, especially one that doesn’t have the proper stewardship – controls must be in place to disable it or deactivate it through the use of a next-generation IGA solution.
How Saviynt Handles Machine Identity Management
Saviynt’s solution secures machine identities through our cloud-based IGA platform.
Highly Scalable, Cloud Architected
Saviynt’s cloud-native platform uses Big Data technologies like ElasticSearch and Hadoop architecturally. We designed our IGA platform to provide tremendous amounts of scale to meet the demand of the number of objects. Organizations need a cloud solution that allows them to manage their machine identities in an efficient way.
Elastic, Extensible Data Model
We designed our platform as an elastic, extensible data model because we found that a lot of machine identities were simplistic while others were more complex. We wanted to offer our customers something that didn’t require code-level customization so that they could create definitions of new objects. Combined with our scalability, Saviynt’s platform provides organizations with the solution to their machine identity risk problems.
Rich Analytics, Peer Insights, and Usage
Saviynt’s analytics allow you to track controls and risk. With peer-to-peer analysis, we can compare whether one machine identity, such as a bot or API, looks like the other machine identities in that same category. If our analytics detect an outlier, they alert your IT administrator to the risky access so that they can review the access and extend governance.
Extensible Process & Workflow Controls
We built a Universal Controls Framework that comes with 200 out-of-the-box policies to help meet compliance mandates, including segregation of duties. The Universal Controls Framework aligns with major regulatory compliance standards such as PCI DSS and HIPAA. Customers leverage these controls to create access policies and extend governance over their machine identities.
Full Lifecycle Management Capabilities
Our platform streamlines the onboarding process offering the ability to manage machine identity access using our fine-grained entitlements. Our platform also enables organizations to create temporary or time-based privilege elevation to limit the scope and time for the machine identity’s access.
Access Review & Certifications
As with all other identity types, customers need to periodically review their inventory for anomalous access, such as whether the RPAs have been executed. In some cases, an RPA may not have been executed, or an API may not have made a call in quite some time. If the machine identity is no longer needed, you may need to determine whether it should continue to exist in your IT environment. With Saviynt’s platform, you gain visibility into these machine identities and can review whether they should be temporarily deactivated, disabled, or even removed from the inventory. The future of IT is no longer a “landscape” but a “cloudscape” that will continue to drive a need for better identity and access governance over machine identities.
Resources


